
In the early age of the Internet, emails became a boom in human communication. Therefore, some bad guys tried to utilize this for their own benefits. They wrote scripts to automatically sign up for a new mail account, then used these accounts to spam other people. There also other scripts were created to submit thousands of requests to a website, such as via form submission, which leads to an overwhelming request handling and temporary shutdown in the server. Hacker also could apply brute-force to send thousands of password guesses to the server, until the password is correct.
In order to tackle this problem, in 2000, a team at Carnegie Mellon University was thinking what if we can introduce a way to differentiate a human and a bot. Inspired by Alan Turing’s test, a bot can be treated as “intelligent” if it can fool a human interrogator to think it’s a human. Then to prove humanness, we need to give a problem that surely no machine be able to solve. Given that computer vision is not very developed at that time, the idea is to generate some random words, adding a little distortion and ask the user to type it back. The distorted word is easy for a human to identify, but it would be a huge task for a bot at that time. The team decided to call it Completely Automated Turing Test to tell Computers and Humans Apart, which is known as CAPTCHA.
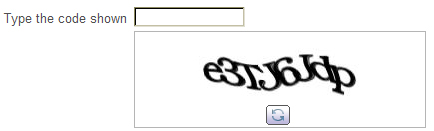
After a while, when computer vision started to develop more, it is used in book/paper scanning and transcribing. However, the accuracy is not really good, because the paper itself may also have some distortion (can be from the ink, font, dust,..) which creates a barrier for the bot. Knowing this, these genius minds start to think, can we apply this captcha to solve this. That’s where reCAPTCHA v1 came up.

In this version, there will be 2 given words. One the computer already knows, the other computer is still confused. Humans, on the other hand, can read these 2 words easily and type it correctly to the box. By doing this, with a number of humans doing the same thing, it helps the computer to actually gain knowledge of the new words, and therefore, improve its efficiency. So with millions of people using CAPTCHA every day in the world, they became somewhat “unpaid labor” (and there was a wave of criticism surrounding CAPTCHA that time) to help digitize the New York Times. Google later bought the company and further utilize these innocent resources for Google Books.
Nowadays, when AI and computer visions start to develop more rapidly, some AI can actually read the distorted words, which can get through these CAPTCHA security gates. So to fight back, Google introduced reCAPTCHA v2, where now user no need to type anything, but just a checkbox “I’m not a robot”.
This looks simple for the user, but how it can tell apart is this user a human or a bot just by a click. The answer is actually the identification process not only starts from when the user clicks the checkbox. Google, via browser, collects all human data (mouse scroll, mouse click, user account, user age, …). Using all these pieces of information, Google can build a machine learning model to predict if the actual human is doing the action. For the specific information they gather and how they analyze it, we never know, unless you are in the team who develop this.
So after analyzing all information, it will produce a confidence score of this user. If they are more towards bot, more challenges will appear. You may then be asked to select some traffic light, crosswalks, bridges in an image. And for sure, these may become another “unpaid labor” for their own benefits. Until our score is more towards humans, the test is passed.
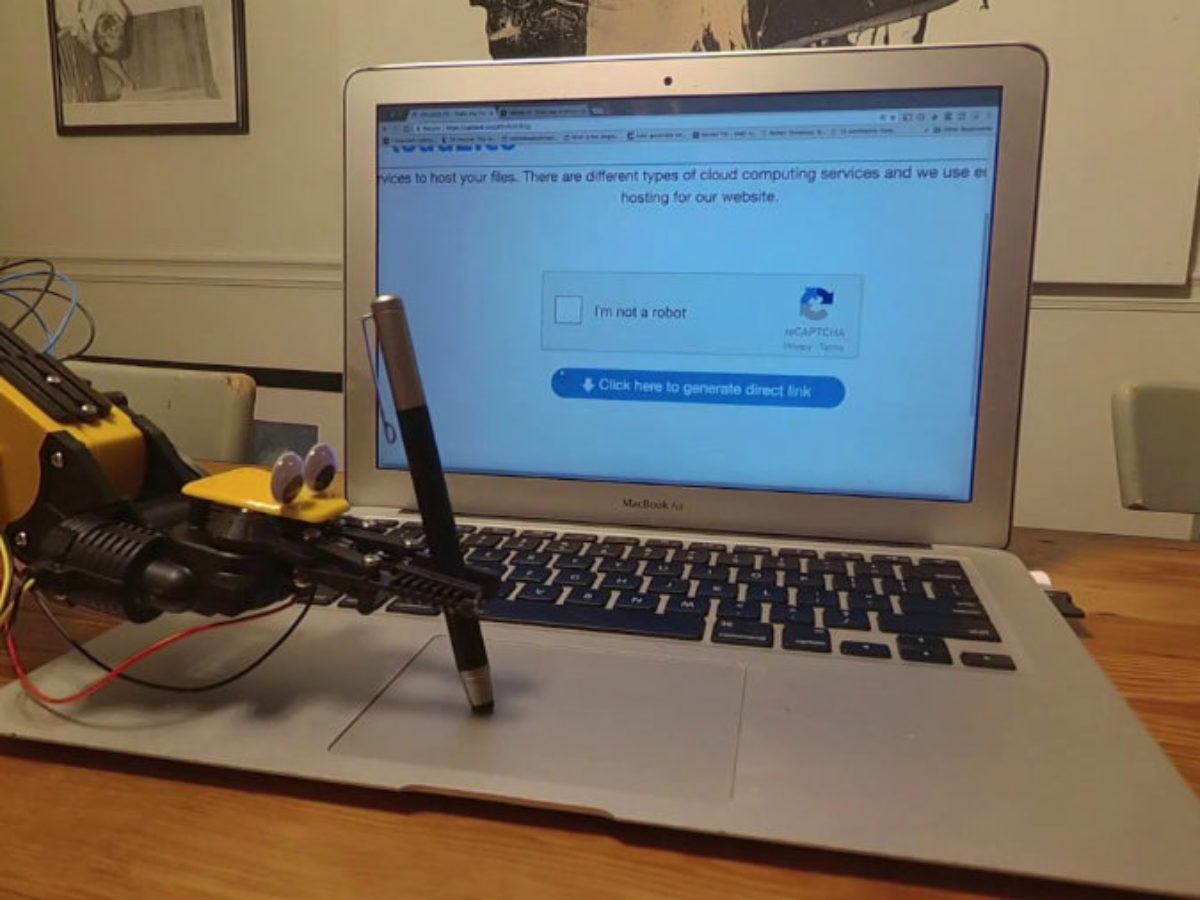
So, to answer the question in the title, the test is very complicated and maybe has started from the moment user open browser/ enter website. Of course, people still can make a robot arm to mimic a human checking this box. But to mimic the whole behavior of mouse scrolling, mouse-clicking,… is a big issue.
For the new update when this post is written, Google is introducing reCAPTCHA v3, which may take a further step, where it removes the need of the user to interact with the box. All the analysis is done behind the scene and will automatically interrupt when it thinks the user is a bot. More info can be found here: https://www.google.com/recaptcha/intro/v3.html
That’s all for today.
This post is not written by a bot.
One response
Really when someone doesn’t be aware of afterward its up
to other visitors that they will assist, so here it takes place.