
In the world when data becomes more and more gigantic and powerful, knowing some modern techniques on how to manipulate data is vital. Elasticsearch is one of them. I write this series to note down what I’ve picked up on the path to studying Elasticsearch.
Part 1: Introduction
Elasticsearch (ES)
Elasticsearch is an open-source analytics and full-text search engine. Let’s take an example when we do searching in an online marketplace, such as Lazada.
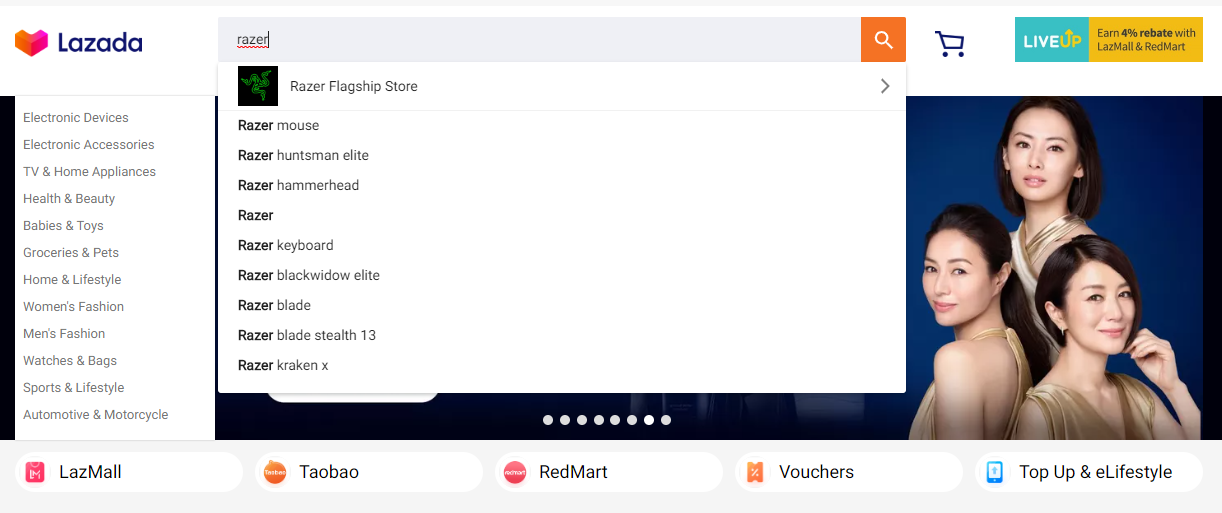
As we can see when a user types in Razer, they don’t need to define whether they are looking for a product name Razer, or a store name Razer, but still, the results will cover all possible cases. Furthermore, it also has one feature called autocomplete which will try to guess what the user is looking for and suggest in the list. Not to mention, this list is usually ordered by some heuristic function, maybe popularity, likes, user customization, …
That is a quick example of Elasticsearch, a very useful and popular technique these days. But it is not all that Elasticsearch can do. With the power of searching, this leads to some use in other fields, especially in data management. People use ES in querying and aggregating data, which then helps them to draw charts, maybe analyzing which product is sold the most. People use ES to store applications/server logs and system metrics, which then helps them to keep track of errors of their website. This is usually referred to as APM – Application Performance Management.
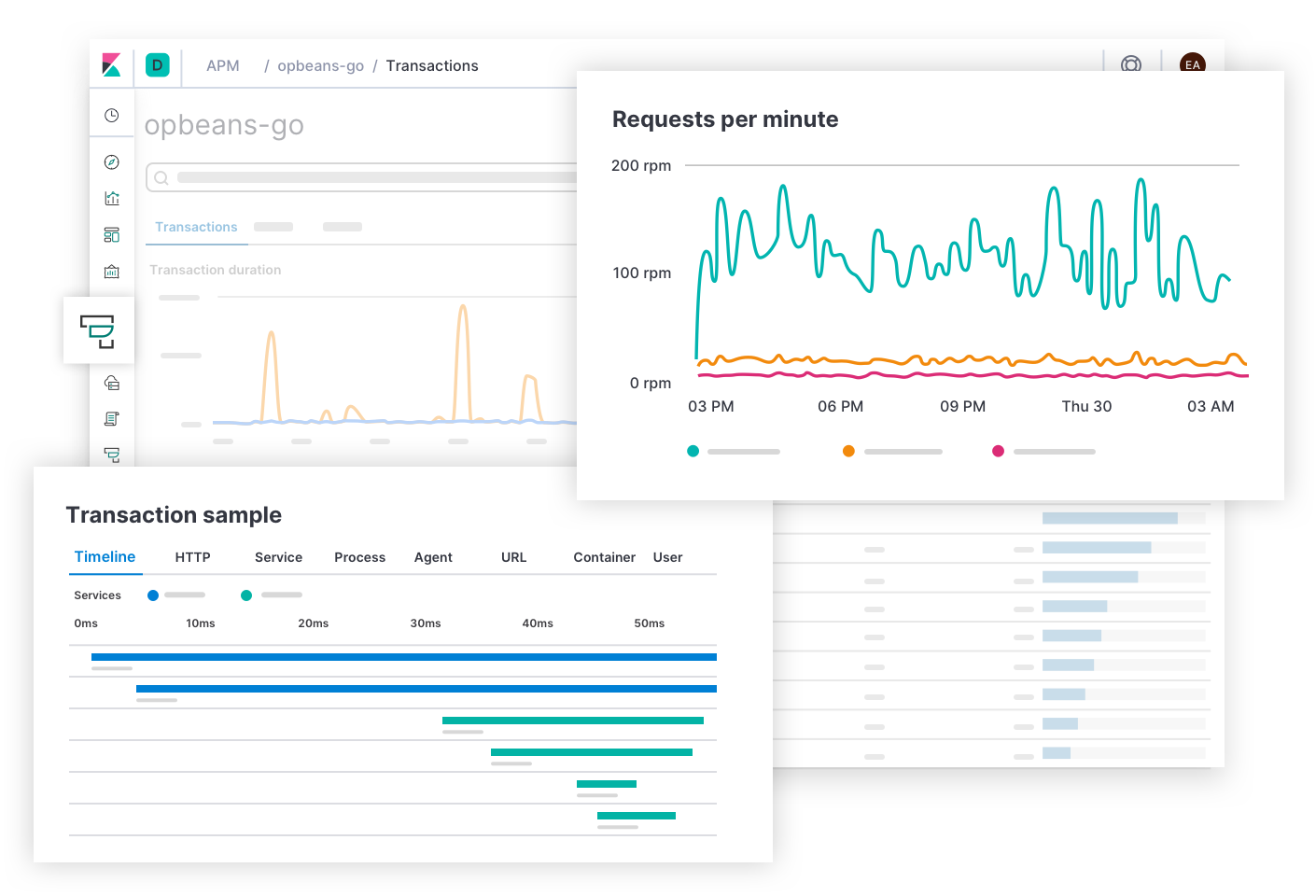
With the current data, people can use ES to do machine learning, to forecast future values, for example, by keeping all order records, we can predict which products will be popular next months. Anomaly Detection is also an example. Let’s say a website usually has 50.000 visitors per day, but now it drops to 1000, this would mean that there is a problem. And we can use machine learning to learn what is the “norm” of our website and will signal us when abnormal things happen.
Data in ES is stored in documents (JSON Object), which is also distributed and scaled easily.
Elastic Stack (ELS)

Together with Elasticsearch, here are some popular techniques: Kibana, Beats, and Logstash.
Kibana (K)
Kibana is an analytics and visualization platform, which lets you easily visualize data from Elasticsearch and analyze it to make sense of it. So K is like a dashboard, where you can go there to view all of the charts about your web performance. You can view all website traffic, browser trends, anomaly detection, future forecast, and many things more here. You can say it looks like a UI, that’s built for the product manager to manipulate data.

Logstash (L)
From the beginning, L is used to collect application logs and send them to ES. However, when things get more developed, we now can use L for a data pipeline, which can send log file entries, e-commerce orders, customers, chat messages, etc. from a log file (CSV, XML, or JSON,…) to many destinations like Kafka, or even an HTTP endpoint.
![Logstash Introduction | Logstash Reference [7.17] | Elastic](https://www.elastic.co/guide/en/logstash/7.17/static/images/logstash.png)
One great thing is in L, we can define some filters here so that the data before sending it to the next destination will be pre-processed. One example is we can use Grok pattern to structuralize a request.
Beats (B)
Beats are data shippers. So in previous sections, we see that people send data from L to other destinations, there are some arrows mapping those ends. Those arrows are Beats.
![Beats overview | Beats Platform Reference [7.6] | Elastic](https://www.elastic.co/guide/en/beats/libbeat/current/images/beats-platform.png)
Some popular B can be mentioned is Filebeat, which is used to collect log files, or Metricbeat, which collects systems metrics (CPU/memory usage).
X-Pack (X)

Some people included X inside the ELS, some not. But it is worth mentioning. X is a plugin manager for ELS. It helps to add some built-in plugin to our ELS, so we don’t need to reinvent the wheels. Some popular plugin can be mentioned here: Security: For authentication and authorization. We can also define roles for many departments on how deep they can manipulate the data. Monitoring: Manage your ELS stack performance. Alerting: Threshold usage. Graph: Find the relative relationship between your data.
A quick note of integration:
An important note here is ELS is completely independent of our web application architecture. This would mean that it’s ok to not having ELS from the beginning, and plug it in when our product scales. Moving back to the example of Lazada’s search box, so the idea is instead of searching in our own database, we will duplicate the data into ES, and doing all data manipulation there.
No responses yet