
In the world when data becomes more and more gigantic and powerful, knowing some modern techniques on how to manipulate data is vital. Elasticsearch is one of them. I write this series to note down what I’ve picked up on the path to studying Elasticsearch.
Part 2: Basic Architecture
There are some basic definitions we need to pick up within ES.
Node
A node is an instance of ES to store a piece of data. Node is not a machine, that’s mean that a machine can start many nodes as we want. However, in production environments, node is usually separated, which runs on a physical/virtual machine, or a docker container.
There are some types of node which can be mentioned:
- Master node: A node is responsible for performing cluster-wide actions. This mainly includes creating and deleting indices, keeping track of nodes, and allocating shards. A quick note that nodes that can perform those actions are not necessarily master node, but need to be elected by voting nodes.
- Data node: A node to store and query data.
- Ingest node: A node to perform ingest pipeline, can be taken as a logstash version inside ES.
- Machine learning node: A node to do machine learning
- Coordination node: A node to handle the distribution of query and aggregation of results.
- Voting node: A node to vote for the master node.
Cluster
![Adding nodes to your cluster | Elasticsearch Reference [7.6] | Elastic](https://www.elastic.co/guide/en/elasticsearch/reference/current/setup/images/elas_0204.png)
A cluster is a collection of related nodes that together contain all of our data. One cluster is usually enough for small scale applications. For bigger applications, or if the developers want to separate business logics, we can create many clusters as we want. For example, we can have one cluster to perform Autocomplete Search and another for APM.
A node will always exist in a cluster, either it joins an existing cluster, or automatically create a new one when born.
Document and Index
Data is stored in documents as JSON Object. In ES, besides the business value, an object is also stored its ES related value, such as id, type, index, etc.
Index is a group of related documents. For example, we can have an index named “products”, and inside this index, there are tons of documents, each storing detail of a product.
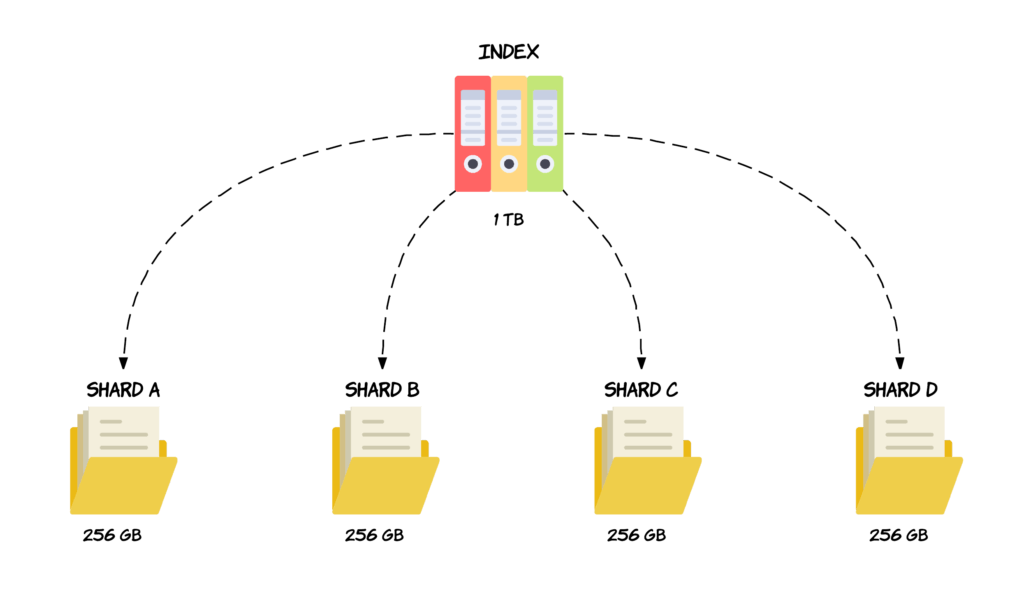
Data Sharding
Data sharding is a popular concept in big data storage, and it is very much of common sense. Let’s take an example when we have an index of 500gb, but each of our node maximum capacity is only 300gb, what should we do then? Of course, we will split the index into 2, let’s say each 250gb and put in each node. That is called data sharding. In more detail, there are 2 types of data sharding: horizontal – split by rows, and vertical – split by columns. One advantage of Data Sharding, of course, is the query performance, by using parallel querying.
Back to ES, an index has one shard by default, and we can increase or decrease number of shards by its API. There is no optimal answer for number of shards should we use, and it should depend on the specific situation. ES shard is Apache Lucene Index ( Inverted Index) – a concept to map content back to its location.
Data Replication
Availability is one of the big challenges in data storage. What if one node/server breaks down and the user wants to query that piece of data. The answer is using data replication. It is simple to understand by its name, yes, we copy the data from one place and store to another. When the main place is down, there is still another backup.
In ES, a shard that has been replicated one or more times is referred to as a primary shard. A primary shard and its replica shards are referred to as a replication group. And of course, to prevent data loss, replica shards are never stored on the same node as their primary shard.
Data Replication only makes sense if the cluster has more than one node. And again, it depends on the situation to know how many replicas are enough.
Data Snapshot
Like taking a picture, a data snapshot is a copy of data at a given point of time. This technique is related to data restoring topics. So there any many chances that when we restore the data from a replica, it may conflicts. This usually happens in a database where we have complicated relationship business logic, and data changes frequently. Restoring one shard makes it inconsistent with others, because, by the time doing so, the data may already be modified. That is where snapshot steps in, to revert the system back to a working state.
If I have time, maybe we can discuss in-depth about these techniques in data, because they are not solely made for ES.
No responses yet